
Big Data
빅데이터 분석 관련하여 비아이매트릭스는 크게 Python과 R를 기반으로 개발을 진행하고 있습니다.
빅데이터 분석 관련하여 비아이매트릭스는 크게 Python과 R를 기반으로 개발을 진행하고 있습니다.
빅데이터 문제를 처리하기 위해 먼저 택한 방법은 Dask 패키지를 사용하는 것입니다.
Dask(http://dask.pydata.org/en/latest/)는 분석 컴퓨팅을 위한 유연한 병렬 컴퓨팅 라이브러리입니다. Dask는 계산을 위해 최적화된 동적 작업 스케줄링(Dynamic task scheduling)과 메모리보다 크거나 분산된 환경으로 확장하는 병렬 배열, 데이터 프레임 및 리스트와 같은 “Big Data” 컬렉션(collections)으로 구성됩니다.
우측 그림예시는 dask 스케줄러가 그리드 검색을 어떻게 실행했는지 보여줍니다. 각 직사각형은 데이터를 나타내고 각 원은 작업을 나타냅니다. 빨간색은 현재 스레드에서 실행되는 작업이거나 메모리를 점유하는 중간 결과를 나타내고 파란색은 완료 또는 해제됨을 의미합니다.
즉, 현재 가용 메모리보다 큰 데이터를 분석하거나 분산 환경으로 구축하고 싶을 때 dask 라이브러리가 도움이 될 것입니다.

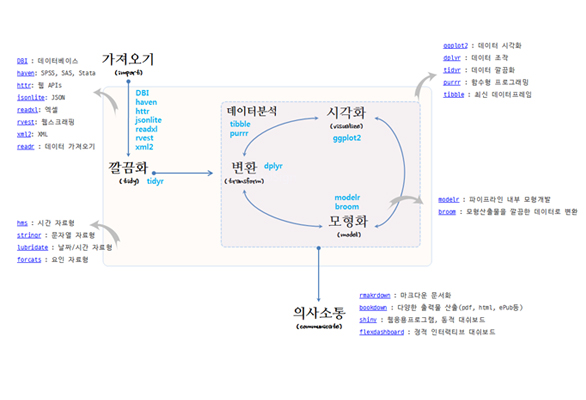
R의 경우에는 최근에 데이터 시각화 전 과정에 필요한 패키지를 tidyverse 패키지가 새로 등록되어 데이터 분석의 많은 부분을 체계화하였습니다. 이 패키지에 관해서 자세히 배울 수 있는 교재는 “R for Data Science” 책을 참고하시기 바랍니다. 참고로 tidyverse 패키지에 포함된 라이브러리는 우측 그림과 같습니다.
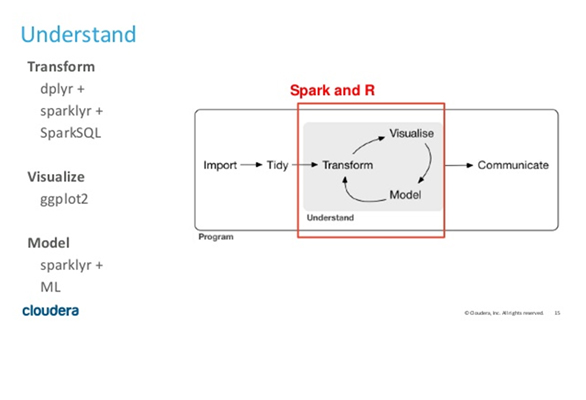
빅데이터 처리를 위해 비아이매트릭스는 sparklyr 패키지를 사용하고 있습니다.
sparklyr는 dplyr을 spark 환경에서 사용할 수 있도록 구현된 패키지입니다.
ggplot2를 이용하여 시각화하기 위해 shinydashboard를 이용하여 개발중에 있습니다. https://rstudio.github.io/shinydashboard/index.html
마지막으로 소개할 연구 분야는 CPU+GPU를 활용하여 고속 cube를 생성하는 기술입니다. pycuda(https://documen.tician.de/pycuda/)와 numba(http://numba.pydata.org/)를 연구중입니다.